
Zero-Disk Architecture: The Future of Cloud Storage Systems
Data Landscape Trends: 2024-2025 Series

This is the third part in the Data Landscape Trends 2024-2025 series, focusing on the evolution of zero-disk architecture.
In the first part, we explored the evolution of the BI stack, while the second part examined the rise of single-node processing engines.
Introduction
The landscape of storage systems is continuously undergoing significant transformations. One major trend in this evolution is the emergence of cloud-native and "zero-disk" architectures for storage systems.
This shift represents a move away from traditional storage systems that rely on locally attached physical storage devices such as HDD, SSD or attached EBS volumes on cloud, towards designs that use remote, scalable object storage services as their primary persistence layer.
Understanding this transformation is crucial for data-intensive businesses as they navigate the future of data infrastructure, particularly as storage costs often account for a significant portion of total cloud infrastructure expenses.
In this article, I will explore the evolution of zero-disk architecture, studying:
The historical context and limitations of traditional storage architectures.
The emergence of disaggregated storage and its evolution in cloud environments.
Economic drivers and technical trade-offs of zero-disk implementations.
Current implementation patterns across different use cases.
Future directions and emerging solutions.

Evolution of Storage Architecture
Traditional Approaches
Before the emergence of disaggregated storage systems, in addition to popular single-node disk-based database systems like MySQL and PostgreSQL, two dominant distributed storage architectures emerged: shared-nothing architecture and shared-disk architecture. Each approach presented unique advantages and challenges which we will explore further.
Shared-Disk Architecture
Early distributed storage systems were built with shared-disk architecture that leverages multiple nodes with independent compute resources (CPU and RAM) while sharing access to a common storage system connected via a network.
While shared-disk architecture provides a simplified data management, this architecture has significant challenges, such as I/O contention, which can become a critical bottleneck during large I/O-intensive ETL workloads due to the shared nature of the I/O subsystem across all nodes in the cluster.
Furthermore, shared-disk systems often necessitate specialised hardware and networking setups, such as Network Attached Storage (NAS) or Storage Area Networks (SAN), which add to the overall cost and complexity.

This design was frequently employed in traditional data warehouses, such as Oracle RAC, to distribute workloads efficiently across multiple servers.
Shared-Nothing Architecture
The shared-nothing architecture, notably outlined by Michael Stonebraker in a published paper in 1986, takes a different approach.
It distributes the system across multiple nodes, where each node operates independently with its own CPU, memory, and disk. Unlike shared-disk systems, nodes in a shared-nothing setup do not share resources, making this architecture highly scalable and efficient for distributed workloads.
One of the key advantages of shared-nothing architecture is its near-linear scalability. Systems can grow seamlessly by adding more nodes, enabling them to handle increased workloads effectively. Additionally, shared-nothing systems are cost-effective, as they rely on commodity hardware rather than expensive, specialised equipment.
However, shared-nothing systems are not without challenges. Managing data distribution is a key hurdle, as hotspots and data skews require careful partitioning and load balancing to ensure optimal performance. Similarly, auto-scaling can be complex and costly, often requiring disruptive operations such as repartitioning and leader-follower replication.

Despite these challenges, shared-nothing architectures have become the backbone of modern disk-based distributed systems like Apache Kafka, Apache Cassandra and DynamoDB. They are also widely used in clustered data warehouses like Teradata and the initial design of Amazon Redshift.
The Emergence of Disaggregated Storage
The journey towards zero-disk architectures and the concept of disaggregated storage and compute began to gain traction with the rise of Hadoop and its associated ecosystem in the mid 2000s.
Hadoop's Distributed File System (HDFS) provided a novel approach to data storage, using commodity hardware to create a highly scalable distributed storage layer with built-in redundancy and fault tolerance.
This architecture laid the foundation for systems that decouple distributed storage from compute, enabling scalability and flexibility. Distributed compute frameworks like MapReduce and Spark operate independently of storage units, processing data stored in HDFS via high-throughput networks.
This architectural pattern evolved into a formalised data architecture, giving rise to modern data lake and, more recently, data lakehouse systems. These systems featured fully decoupled storage and compute layers, contrasting with the tightly integrated approach of traditional monolithic database systems:

Early Zero-Disk Systems
A new class of storage systems, including HBase, Solr, Hive, and Ignite, emerged within the Hadoop ecosystem using this paradigm, leveraging HDFS as their primary storage abstraction.
This new paradigm presented a new database architecture pattern:
Beyond the key advantage of decoupling compute and storage—allowing each to scale independently—these disaggregated storage systems could offload complex low-level storage tasks, such as disk management, data replication, and durability, to a dedicated deep storage service.

Furthermore, this approach acknowledges that storage and compute requirements often grow at different rates. In practice, storage needs tend to increase rapidly as organisations collect more data, while compute demands may remain relatively stable, especially if the nature of data analysis remains unchanged.
The Rise of Cloud Storage
Hadoop-based decoupled storage systems revolutionised data infrastructure by separating compute and storage layers. However, managing these systems introduced significant challenges due to the operational complexity of running and maintaining large Hadoop clusters in data centers.
Organisations needed to hire highly sought-after Hadoop experts, a resource that was scarce and costly. While large tech companies like Yahoo, LinkedIn, and Twitter could afford this, smaller organisations and non-tech companies often faced difficulties in scaling and operating Hadoop effectively.
In a petabyte-scale on-premise Hadoop platform, we have operational challenges as part of routine activities. These include managing regular disk failures and replacements, rebalancing data across nodes when new nodes are added or removed, and addressing performance issues caused by slow data nodes as disk utilisation approaches critical thresholds (typically around 80%). Additionally, maintaining and scaling the Name Node master services as workloads and data volumes grow is a critical task.
Emergence of Amazon S3 Storage
The emergence of Amazon S3 and the growing momentum of cloud adoption in 2010s provided a transformative alternative.
Cloud object storage services like Amazon S3 offered a simpler, more scalable, and cost-effective solution for building big data applications, gradually replacing Hadoop HDFS in many scenarios.
In addition to eliminating the operational complexities of managing and scaling HDFS, cloud storage offers several key advantages:
High Availability: Cloud storage providers typically guarantee up to 99.99% availability, whereas on-premises HDFS systems often experience regular downtimes due to maintenance, crashes, and hardware or software upgrades.
Elasticity: Cloud storage removes the need for advance capacity planning, which often results in inaccurate resource estimates, and eliminates upfront hardware procurement costs.
Unlimited Scalability: Cloud storage provides virtually infinite scalability without the need for regular capacity planning and hardware procurement.
Multi-Tier Storage: Cloud storage offers different storage classes with seamless data migration between them, enabling cost optimisation.
Cost Efficiency: The total cost of ownership for cloud storage, such as Amazon S3, is generally lower than on-premises storage like HDFS, which incurs a 3x replication overhead.
True Zero-Disk Architecture: Cloud storage supports running multiple permanent or ephemeral compute clusters on a shared storage infrastructure, enabling a truly zero-disk architecture.
The success of decoupled storage and compute architectures in Hadoop platforms and the benefits of the new cloud storage inspired industry to replicate the same architecture on cloud.
Instead of relying on HDFS, new systems would leverage S3 as the primary storage backend, paired with cloud compute for processing power. This innovation gave birth to what we now recognise as cloud-native architectures.

Netflix was among the first adopters to replace HDFS with Amazon S3 on its Hadoop clusters running on AWS in the early 2010s. They utilised S3 as the central data lake storage, while Hive and Spark served as the compute engine operating on Amazon EMR clusters.
The Rise of Cloud-Native Data Vendors
The launch of two major cloud data vendors, Databricks in 2013 and Snowflake in 2014, both embracing the decoupled compute and storage model with cost-effective cloud storage as the foundation, signaled further solidification of the new storage paradigm.
Snowflake, in particular, emerged as an early pioneer in implementing a fully decoupled, commercial cloud-native data warehouse. Their influential paper published in 2016, introduced key innovations that redefined cloud-based data warehousing, demonstrating how object storage systems like Amazon S3 could serve as the primary storage layer for durability and scalability.
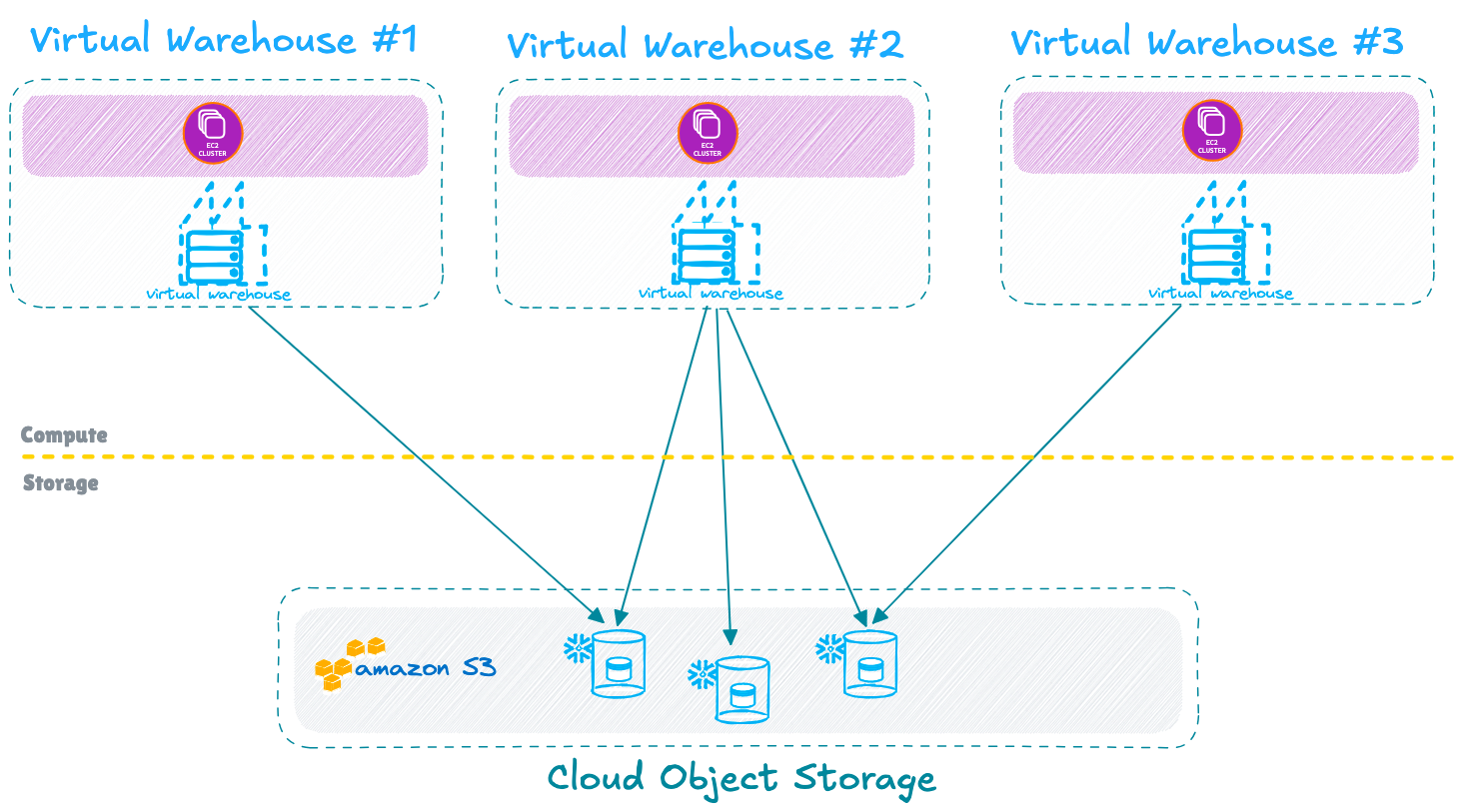
The paper also introduced a novel multi-cluster shared data architecture, enabling diverse workloads—analytics, reporting, and ETL—to run as separate compute clusters on a single shared data platform.
This approach, known as "virtual warehouses" in Snowflake's terminology, proved highly influential, inspiring other vendors like Amazon Redshift to adopt similar design.
The Zero-Disk Paradigm
The rise of cloud-native big data processing, coupled with the maturation of cloud object storage as a universal storage backbone, has driven a shift towards a true 'zero-disk' architecture.
In a full zero-disk architecture, compute units or workers operate as stateless entities without attached storage. Persistent data is stored in cloud object storage, which offers high durability, availability, and scalability out-of-the-box. This decoupling simplifies auto scaling as compute demand fluctuates, enabling virtually infinite scalability for both storage and compute.
Unlike disk-based distributed systems that rely on shared-nothing architectures—requiring complex operations like load balancing and partition reassignment—zero-disk systems eliminate such overhead.

Before exploring the current landscape of zero-disk database systems further, let's examine the some of the key trade-offs in disk-based vs cloud-native zero-disk architecture.
The Economics of Zero-Disk Architecture
A key driver for adopting zero-disk architecture is the potential for substantial cost reduction.
From a storage cost perspective, local SSDs attached to VMs and even durable EBS volumes are significantly more expensive than cloud object storage. For instance, storing three replicas on attached storage can cost 10-20x more per GB compared to using cloud object storage.
Beyond the cost per GB, disk-based storage systems face additional expenses from cross-availability zone (AZ) data transfer fees when deployed in high availability mode with replication across multiple AZs. These inter-zone networking costs can significantly inflate operational budgets.
As Claimed by WarpStream, a cloud-native alternative to Kafka, and acknowledged by Redpanda and Confluent, infrastructure costs for running such systems in the cloud can account for 70% to 90% of total infrastructure and workload expenses. This is largely due to inter-zone networking overhead for replicating data between Availability Zones.
In contrast, distributed zero-disk systems like WarpStream leverage object storage (e.g., Amazon S3) as the backbone, claiming to reduce total cost of ownership (TCO) by 5-10x compared to Kafka.

For example, WarpStream reports that it can eliminate $641/day in inter-zone networking fees in a typical Kafka production deployment, replacing it with less than $40/day in object storage API costs. Similarly, Redpanda acknowledges the difficulty of escaping such hidden costs in traditional replicated systems.
Technical Trade-offs: Disk-Based vs. Zero-Disk
The fundamental trade-off in zero-disk architecture can be summarised as: "relaxing latency requirements to leverage cloud durability and economics of scale".
This trade-off manifests in several key areas:
1. Performance Characteristics
Traditional local disk-based storage offers fast access speeds (both for reads and writes) and high IOPS rate, but often lacks inherent scalability and redundancy features. To achieve durability and protection against data loss, disk-based systems require complex setups like RAID and software-level replication for fault tolerance.
Zero-disk storage systems, on the other hand, leverage the inherent redundancy and fault tolerance of object stores. Deep object storage systems provide safety guarantees, fault tolerance, and versioning out-of-the-box.
This simplifies system design, removing the requirement to manage data replication, backups, and snapshots to protect against data loss or disasters. However, the price for these benefits is the higher access latency, largely due to inherent object storage design and network I/O.
2. Directory and File listing Bottleneck
Listing operations for directories and files have been a significant performance bottleneck in distributed filesystems and cloud object stores. This challenge particularly affects large-scale data systems that need to manage extensive collections of files and partitions.
In query execution, the planning phase can sometimes exceed the actual processing time, especially when dealing with heavily partitioned datasets and large number of small data files.
Those who have worked with query engines like Hive operating on large HDFS cluster may have seen queries which require several minutes just to complete bulk listing operations, and gathering required metadata for all relevant files and partitions before processing can begin.
3. API call Limits
The challenge is further compounded by rate-limiting and throttling mechanisms implemented by cloud providers. Cloud object stores impose various operational limits that require careful consideration:
Amazon S3, for example, imposes a limit of 1,000 objects per LIST request when using prefix listing functionality. To overcome this limitation, systems must execute hundreds of parallel calls, and use random prefixes, while each operation typically requiring between tens and hundreds of milliseconds to complete.
S3 has a limit of 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in a bucket. Therefore prefix management and distribution is important to get the level of horizontal scalability and parallelism required in large scale data applications when processing data on S3.
Mitigating Access Latencies
The higher latency associated with cloud object storage is a crucial challenge, particularly for real-time applications. Several techniques are currently used to mitigate this:
External Metadata Management - To address the high latencies associated with listing files and directories, it is possible to explicitly maintain metadata records for files and partitions to alleviate this bottleneck. Open Table Formats like Apache Iceberg, Hudi, and Delta Lake store file and partition metadata in log files, minimising expensive API calls during the query planning phase by providing direct access to this information.
Local Caching: Compute nodes can use fast local storage (e.g., NVMe SSDs) as a read-through and write-through cache. This reduces latency by storing hot data locally, and serving writes before flushing to object stores.
Exploiting Throughput: Leveraging the high throughput of object stores by using multiple I/O threads can help improve access speed by executing many parallel I/O operations.
Express Object Storage: New types of object storage, such as Amazon S3 Express One Zone, offering lower latency but with higher costs.
These approaches aim to balance the benefits of cloud object storage with the performance needs of various applications.

Implementation Patterns
Different use cases have led to distinct implementation patterns for zero-disk architecture, each addressing specific requirements and constraints.
Analytical Workloads on Deep Storage
As previously highlighted, analytical systems were among the pioneers in adopting zero-disk architecture, largely due to their ability to tolerate higher latencies.
Distributed Compute frameworks like Hive, Spark, and Presto/Trino have been processing petabyte-scale analytical workloads on cloud-based data lakes for over a decade.
The emergence of Snowflake and the adoption of a similar decoupled architecture by Redshift and BigQuery further advanced the implementation of OLAP database systems on deep storage. These platforms demonstrated how separating storage and compute could deliver scalability and flexibility without compromising performance.
To address challenges such as latency and API call overhead, several optimisation techniques are used including external metadata management to reduce expensive API calls, using efficient columnar storage formats like Parquet optimised for cloud object stores, and parallel processing to leverage high throughput capabilities to deliver high performance while benefiting from the cost efficiency and scalability of cloud-native architectures.
Building on the success of major vendors, the database industry has increasingly embraced this architectural shift, with numerous implementations emerging in recent years and 2024 in particular.
A recent example is the release of InfluxDB 3.0, announced in 2024, which represents a comprehensive architectural overhaul. This revamped system leverages Apache Arrow for in-memory buffering and Parquet as the storage format stored on remote cloud storage service.
Transactional Systems on Deep Storage
While zero-disk architecture has shown considerable success with analytical workloads and offline systems such as data warehouses, implementing transactional systems presents unique challenges.
OLTP database systems demand strict ACID properties and sub-second latency requirements, including the ability to perform fast in-point updates. These requirements create significant challenges when working with immutable storage layers with high I/O latencies that weren't designed for small random writes and updates.
Core Challenges
Several fundamental limitations of cloud object stores make implementing full ACID guarantees challenging:
Eventual Consistency
Prior to AWS S3's introduction of strong consistency in 2021, all INSERT, PUT, and DELETE operations were eventually consistent. This limitation could lead to inconsistencies where changes were not immediately visible due to the lack of strong read-after-write consistency—a critical requirement for transactional systems.
Lack of Mutual Exclusion
The lack of mutual exclusion capabilities in object stores presents another significant hurdle. Without built-in support for concurrent writes or "put-if-absent" guarantees, systems risk data loss or corruption from simultaneous writes to the same location.
Modern object storage frameworks like Apache Hudi and Delta Lake have addressed this by implementing external locking services, using systems like DynamoDB to manage concurrent writes to S3.
A significant development occurred in 2024 when AWS introduced "Conditional Writes" for S3, enhancing reliability and efficiency for data operations in S3 object storage. This feature ensures writes only occur if certain conditions are met, reducing the risk of unintentional data overwrites and improving concurrency control.
Non-Atomic File Operations
Traditional systems like HDFS handle file renaming as fast, atomic metadata operations. In contrast, cloud object stores must physically copy and delete data to achieve the same result. This limitation significantly impacted systems such as Hive, Spark, and HBase that rely on atomic rename operations for managing data files.
Given the constraints outlined above, is it feasible to design a general-purpose transactional database system, such as PostgreSQL, that utilises object storage as its primary storage layer? Let’s find out.
Hybrid Architecture Solution
While implementing fully zero-disk transactional systems remains challenging, a hybrid architecture has emerged as a practical solution.
This approach uses a fast replicated write cache combined with periodic offloading to deep storage, based on the LSM-Tree algorithm found in modern key-value stores like Cassandra and RocksDB.
The LSM-Tree architecture, originally designed to eliminate high I/O latencies from random I/O operations on HDDs, proves equally valuable for cloud storage systems.
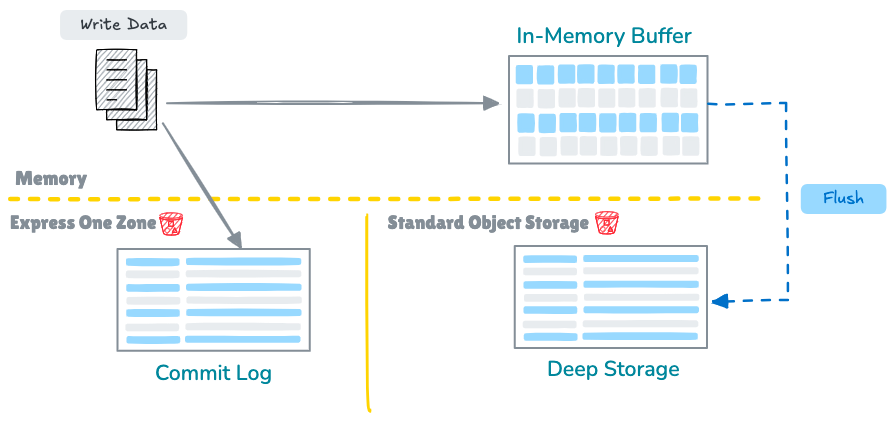
This design helps manage both the high I/O latencies and lack of transactional primitives in cloud storage services. Key components include:
A write-ahead log (WAL) maintained on local storage (such as EBS volumes) for atomic update guarantees.
In-memory caching with periodic flushing to object storage to eliminate the high I/O cost of performing real-time updates.
Query execution that reconciles both in-memory cache and object store data.
This architecture effectively addresses the high IOPS requirements of traditional database systems, which typically make numerous small changes at the page level.
Several modern systems have successfully implemented variations of this approach:
Neon's Serverless PostgreSQL implementation uses this pattern in its cloud-native database.
AutoMQ employs EBS volumes for write caching and WAL while continuously offloading data to remote storage.
SlateDB embedded database implements an LSM-Tree architecture directly on cloud storage.

Future Directions
The general availability of S3 Express One Zone, announced in 2023, offering single-digit latency, suggests potential future developments for transactional workloads on deep storage. This service could potentially replace the replicated write cache layer presented in the hybrid architecture, enabling fully zero-disk transactional systems.
However, its current limitations—including costs seven times higher than standard S3 and single-zone replication—mean that hybrid approaches are likely to remain prevalent in the near term.
Real-Time Systems on Deep Storage
Similar to OLTP database systems, real-time event-based systems like Apache Kafka rely on fast I/O and certain ACID guarantees.
Constructing low-latency, real-time systems on deep storage presents unique challenges, as traditional disk-based systems depend on high IOPS and low-latency sequential I/O. Writing directly to cloud storage can introduce latencies in the hundreds of milliseconds, which is unacceptable for many real-time scenarios.
One solution is to mirror the approach presented for transactional systems: combining intermediate fast local write caches with periodic flushing to deep storage using LSM-Tree architecture.
AutoMQ implements this strategy by using EBS volumes for write-ahead logging while periodically offloading data to object stores. This architecture allows them to achieve single-digit millisecond P99 latency while still benefiting from cloud storage economics.

Full Zero-Disk Implementation
You might ask, is it possible to completely eliminate intermediate cache for real-time event-driven systems and go fully zero-disk?
Yes, but this requires accepting the primary trade-off: increased latency.
As WarpStream co-founder argues:
If you can tolerate a little extra latency, Zero Disk Architectures (ZDAs), with everything running directly through object storage with no intermediary disks, are better. Much better.
WarpStream represents a pioneering implementation of this approach. Built as a Kafka-compatible platform directly on cloud storage, it demonstrates both the possibilities and trade-offs of full cloud-native zero-disk architecture to take advantage of the cloud economics and eliminate exorbitant cost of running Kafka on cloud.
The founder asked:
“What would Kafka look like if it was redesigned from the ground up today to run in modern cloud environments, directly on top of object storage, with no local disks to manage, but still had to support the existing Kafka protocol?”
The system uses stateless "Agents" instead of traditional brokers, eliminating the need for JVM management and rebalancing operations. However, it accepts higher latencies—around 600ms for write confirmation and over one second for end-to-end operations—in exchange for significantly lower costs and operational simplicity.
For organisations willing to accept slightly higher latency, WarpStream offers a massively simplified and far more cost-effective, cloud-native alternative to Kafka.
This innovative design, combined with its Bring Your Own Cloud (BYOC) deployment model that fully decouples compute from storage, attracted Confluent, which acquired WarpStream in 2024 to integrate its groundbreaking architecture into Confluent's offerings, further expanding deployment options.
Industry Evolution
Beyond WarpStream, the real-time pub/sub industry has seen rapid evolution in this space:
Pinterest led early adoption, implementing an in-house Kafka alternative pub/sub system called MemQ in 2020 that proved to be 90% cheaper than traditional Kafka deployments with three-way replication across availability zones.
Redpanda made cloud storage their default storage tier in 2022, adopting a cloud-first approach. In 2024, they introduced Cloud Topics where data is written directly to cloud storage while only metadata is replicated across availability zones.
As highlighted earlier, AutoMQ launched in 2023 as a zero-disk Kafka alternative aims to replace disk with object storage as the persistence layer while maintaining the same performance and access latencies by using locally attached cache.
Confluent's trajectory shows the industry's direction. They announced Kora in 2023, a proprietary cloud-native engine, followed by Freight Clusters in 2024. These innovations enable direct writing to object storage, eliminating costly cross-AZ broker replication for workloads that can tolerate higher latency, achieving up to 90% cost reduction compared to traditional deployments.
Real-Time OLAP and Stream Processing
The trend extends beyond messaging systems. Apache Doris 3.X, released in late 2024, introduced compute-storage decoupled deployment mode for its OLAP engine, enabling the storage layer to operate on low-cost storage like HDFS and S3.
StarRocks OLAP engine v3.0, launched in 2023, introduced a shared-data cluster featuring a storage-compute separation architecture, enabling data persistence into S3-compatible object storage.
In 2024, StarRocks announced preview support for AWS Express One Zone as storage volume in version 3.3, to significantly enhance read and write performance on cloud storage.
ClickHouse Inc launched ClickHouse Cloud in 2022, with a separate storage and compute architecture, optimised for storing data on shared cloud object store , while using local NVMe SSDs for caching layer both for reads and write paths in order to mitigate the added access latency introduced by the object storage.
Apache Flink's 2.0 release in late 2024 marked another milestone, introducing a cloud-native architecture for state management. This replaced their previous complex tiered storage approach with a simpler model using deep storage as the primary storage layer and local disks as optional cache.
The Future of Real-Time Systems
The evolution of real-time systems on deep storage reveals a clear trend:
Organisations are increasingly willing to accept higher latencies in exchange for dramatic cost reductions and operational simplicity. This shift is particularly notable in high-throughput workloads like log ingestion, where sub-second latency isn't critical.
The success of these implementations suggests that the future of real-time systems might involve a spectrum of solutions, from hybrid approaches that prioritise performance to full zero-disk implementations that optimise for cost and simplicity.
The choice between these approaches will likely depend on specific use cases and latency requirements rather than technical limitations.
Other Emerging Patterns and Solutions
In addition to the growing adoption of zero-disk architecture, other emerging architectural patterns are leveraging cloud storage without fully transitioning to a zero-disk model.
Heterogenous Tiered Storage
Modern systems are implementing sophisticated tiered storage strategies to balance performance and cost.
Cheap deep storage provides a compelling choice for long-term storage of historical cold data or alternatively provide a read-only replica outside of the main storage system to external query processors.
Beyond established storage engines like Apache Druid and Pinot, which utilise external deep storage to offload older data segments, a growing number of disk-based storage systems have adopted similar approaches in recent years.
Redpanda introduced their Archival Storage subsystem in 2021, enabling automatic movement of data between tiers, which moves large amount of data between the brokers and the remote cloud storage automatically with the objective of providing infinite data retention with good performance at a low cost,
Apache Kafka has also embraced this approach. With the release of Kafka 3.6 in 2023 initially proposed by Uber, the platform introduced tiered storage support with pluggable remote storage options. The system allows for configurable retention policies per tier and automates segment migration between storage layers.

Crunchy Data implemented a feature in their managed PostgreSQL service to copy data into the data lake for cheaper and long term storage supporting Parquet format.
Remote Read Replicas
Redpanda's Remote Read Replica functionality, introduced in 2022, represents another innovative approach to leveraging object storage in a semi-disk-based approach.
This feature enables separate consumer clusters to access archived data without impacting primary production clusters. It also allows for the integration of topics from multiple production clusters, providing unified read-only access for downstream consumers.
While the implementation of tiered storage and remote read replica by disk-based software systems such as Kafka and Redpanda try to take advantage of cloud-storage economics without a full re-architecture of their systems, however it still doesn't live up to the promise of reduced total cost and simplicity offered by a full zero-disk architecture.
Conclusion
The rise of zero-disk architecture represents a fundamental shift in storage system design, driven by cloud economics and the maturation of distributed object storage. While this approach introduces certain trade-offs, particularly around latency, the benefits in terms of cost reduction, operational simplicity, and built-in reliability make it an increasingly attractive option for modern applications.
As cloud infrastructure continues to evolve and new techniques for managing latency emerge, the balance between performance and cost will likely continue to shift in favour of zero-disk architectures, particularly for organisations prioritising cost optimisation over sub-second latency requirements.
Recent industry developments further demonstrate the momentum behind zero-disk architectures. The introduction of cloud-native Kafka solutions like Confluent's Kora and Freight Clusters, which integrate directly with object stores in 2024, along with Confluent's acquisition of WarpStream, the launch of Flink 2.0 with a cloud-native architecture, The full re-architecture of InfluxDB, and Redpanda's emphasis on cloud-first strategies and cloud topics, all signal a growing shift toward cloud-native, zero-disk architectures as a dominant paradigm for modern storage systems.
