


Open Source Data Engineering Landscape 2025
A comprehensive view of active open source tools and emerging trends in data engineering ecosystem in 2024-2025

Introduction
The open source data engineering landscape continues to evolve rapidly, with significant developments across storage, processing, integration, and analytics in 2024.
This marks the second year the open source data engineering landscape is published. The goal is to identify and showcase key active projects and prominent tools in the data engineering space, and provide a comprehensive overview of the dynamic data engineering ecosystem, key trends and developments.
While this landscape is published annually, the accompanying GitHub repository is updated regularly throughout the year. Feel free to contribute if you notice any missing component.
Research Methodology
Conducting such extensive research demands considerable effort and time. I continuously research and strive to stay informed about significant developments in the data engineering ecosystem throughout the year, including news, activities, trends, reports, and advancements.
Last year, I built my own little data platform to track GitHub public repository events, enabling better analysis of GitHub-related metrics of open source tools such as code activity, stars, user engagement, and issue resolution.
The stack includes a data lake (S3), Parquet as the serialisation format, DuckDB for processing and analytics, Apache NiFi for data integration, Apache Superset for visualisation, and PostgreSQL for metadata management, among other tools. This setup has allowed me to collect approximately 1TB of raw GitHub event data, consisting of billions of records, along with an aggregated dataset that rolls up daily, totaling over 500 million records for 2024.
Tool Selection Criteria
The available open source projects for each category are obviously vast, making it impractical to include every tool and project in the presented landscape.
While the GitHub page contains a more comprehensive list of tools, the annually published landscape only contains active projects, excluding inactive and fairly new projects with no minimal maturity or traction. However not all included tools may be fully production-ready; some are still on their journey toward maturity.
Without further ado, here is the 2025 Open Source Data Engineering Landscape:

State of Open Source in 2025
The open source data engineering ecosystem experienced substantial growth in 2024, with over 50 new tools added to this year's landscape while removing approximately 10 inactive and archived projects. Although not all these tools launched in 2024, they represent important additions to the ecosystem.
While this growth demonstrates continued innovation, the year also saw some concerning developments regarding licensing changes. Established projects including Redis, CockroachDB, ElasticSearch, and Kibana transitioned to more closed and proprietary licenses, though Elastic later announced a return to open source licensing.
However, these shifts were balanced by significant contributions to the open source community from major industry players. Snowflake's contribution of Polaris, Databricks' open sourcing of Unity Catalog, OneHouse's donation of Apache XTable, and Netflix's release of Maestro demonstrated ongoing commitment to open source development from industry leaders.
The Apache Foundation maintained its position as a key steward of data technologies, actively incubating several promising projects throughout 2024. Notable projects in incubation included Apache XTable (universal table format), Apache Amoro (lakehouse management), Apache HoraeDB (time-series database), Apache Gravitino (data catalog), Apache Gluten (Middleware), and Apache Polaris (data catalog).
The Linux Foundation has also strengthened its position in the data space, continuing to host exceptional projects such as Delta Lake, Amundsen, Kedro, Milvus, and Marquez. The foundation expanded its portfolio in 2024 with new significant additions, including vLLM, donated by the University of California, Berkeley, and OpenSearch, which was transferred from AWS to the Linux Foundation.
Open Source vs Open Core vs Open Foundation
Not all of the projects listed are fully interoperable, vendor-neutral open source tools. Some operate under an open core model, where not all components of the complete system are available in the open source version. Typically, critical features such as security, governance, and monitoring are reserved for the paid versions.
Questions remain about the sustainability of the open core business model. This model faces significant challenges, leading some to believe it may give way to the Open Foundation model. In this approach, open source software serves as the backbone of commercial offerings, ensuring that it remains a fully viable product for production with all the necessary features.
Overview of Categories
The data engineering landscape is divided into 9 major categories:
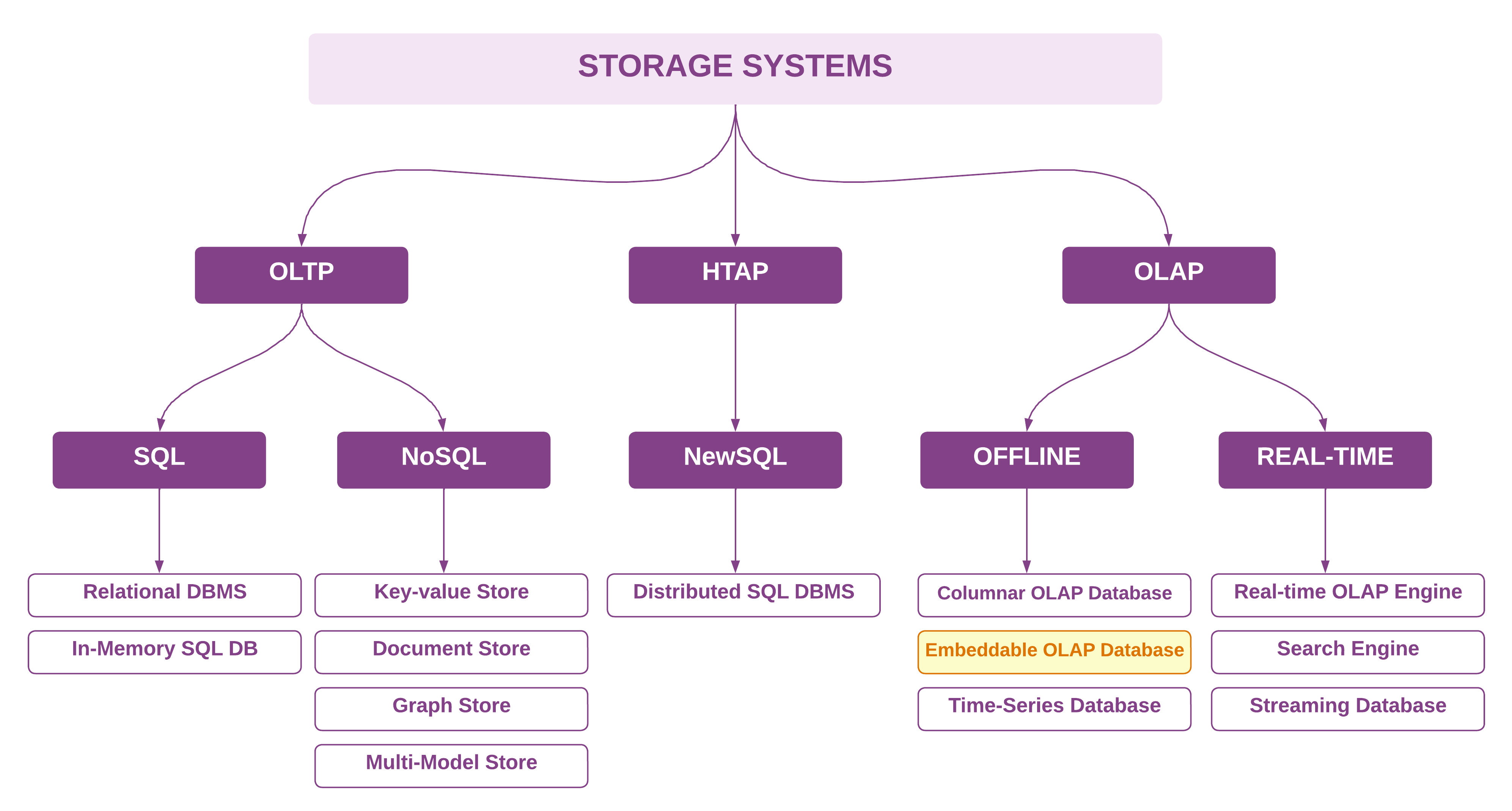
Storage Systems: Databases and storage engines spanning OLTP, OLAP, and specialised storage solutions.
Data Lake Platform: Tools and frameworks for building and managing data lakes and lakehouses.
Data Processing & Integration: Frameworks for batch and stream processing, plus Python data processing tools.
Workflow Orchestration & DataOps: Tools for orchestrating data pipelines and managing data operations.
Data Integration: Solutions for data ingestion, CDC (Change Data Capture), and integration between systems.
Data Infrastructure: Core infrastructure components including container orchestration and monitoring.
ML/AI Platform: Tools focused on ML platforms, MLOps and vector databases.
Metadata Management: Solutions for data catalogs, governance, and metadata management.
Analytics & Visualisation: BI tools, visualisation frameworks, and analytics engines.
In the following section latest trends, innovations and current state of major products in each category is briefly discussed.
1. Storage Systems
The storage systems landscape has seen significant architectural advancements in 2024, particularly in the realm of OLAP database systems.
DuckDB emerged as a major success story, particularly following its 1.0 release that demonstrated production readiness for enterprise use. The new embeddable OLAP category has expanded with new entrants like chDB (built on ClickHouse), GlareDB, and SlateDB, reflecting growing demand for lightweight analytical processing capabilities.
OLAP Extensions & HTAS
A significant development has been the proliferation of new OLAP extensions, especially in the PostgreSQL ecosystem.
These extensions allow to seamlessly extend OLTP databases, transforming these systems into HTAP (Hybrid Transactional/Analytical Processing) or new HTAS (Hybrid Transactional Analytical Storage) database engine that integrate headless data storage—like data lakes and lakehouses—with transactional database systems.
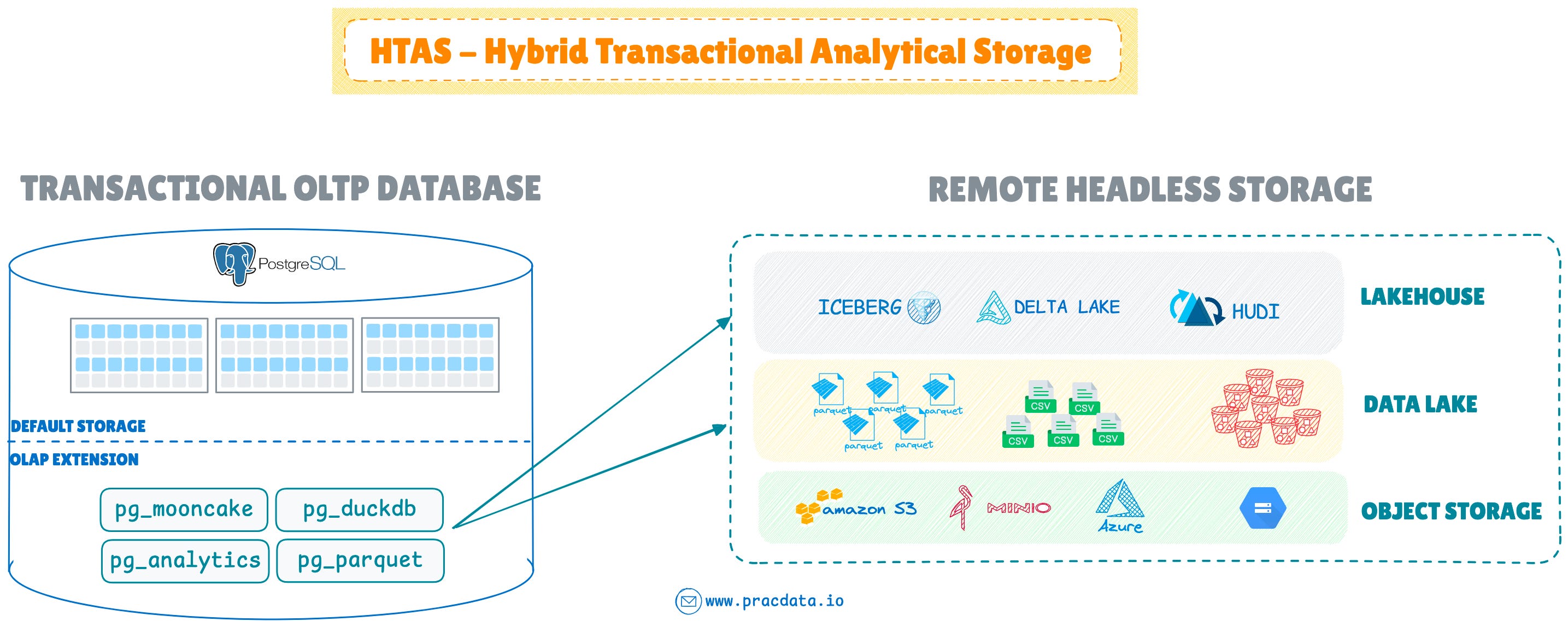
MotherDuck's release of pg_duckdb represented a major advancement, enabling DuckDB to serve as an embedded OLAP engine within PostgreSQL. The pg_mooncake extension followed, providing native column store capabilities in open table formats like Iceberg and Delta. Crunchy Data and ParadeDB made similar contributions through pg_parquet and pg_analytics respectively, enabling direct analytics over Parquet files on data lakes.
Zero-Disk Architecture
The zero-disk architecture emerged as perhaps the most transformative trend in storage systems, fundamentally changing how database systems manage storage and compute layers.
This architectural approach completely eliminates the need for locally attached disks, instead using remote deep storage solutions like S3 object storage as the primary persistence layer.
Beyond OLAP storage systems, such as cloud data warehouses and open table formats, we are witnessing a significant emergence of this pattern in NoSQL, real-time, streaming and transactional systems.
The primary trade-off for disk-based vs zero-disk systems is cost vs performance, and the I/O latency for reading and writing data to the physical storage. While disk-based systems can manage fast sub-millisecond I/O, the zero-disk systems achieve economics of scale with cheap scalable object storage, at the cost of facing latencies up to one second when reading and writing data to a an object storage service.
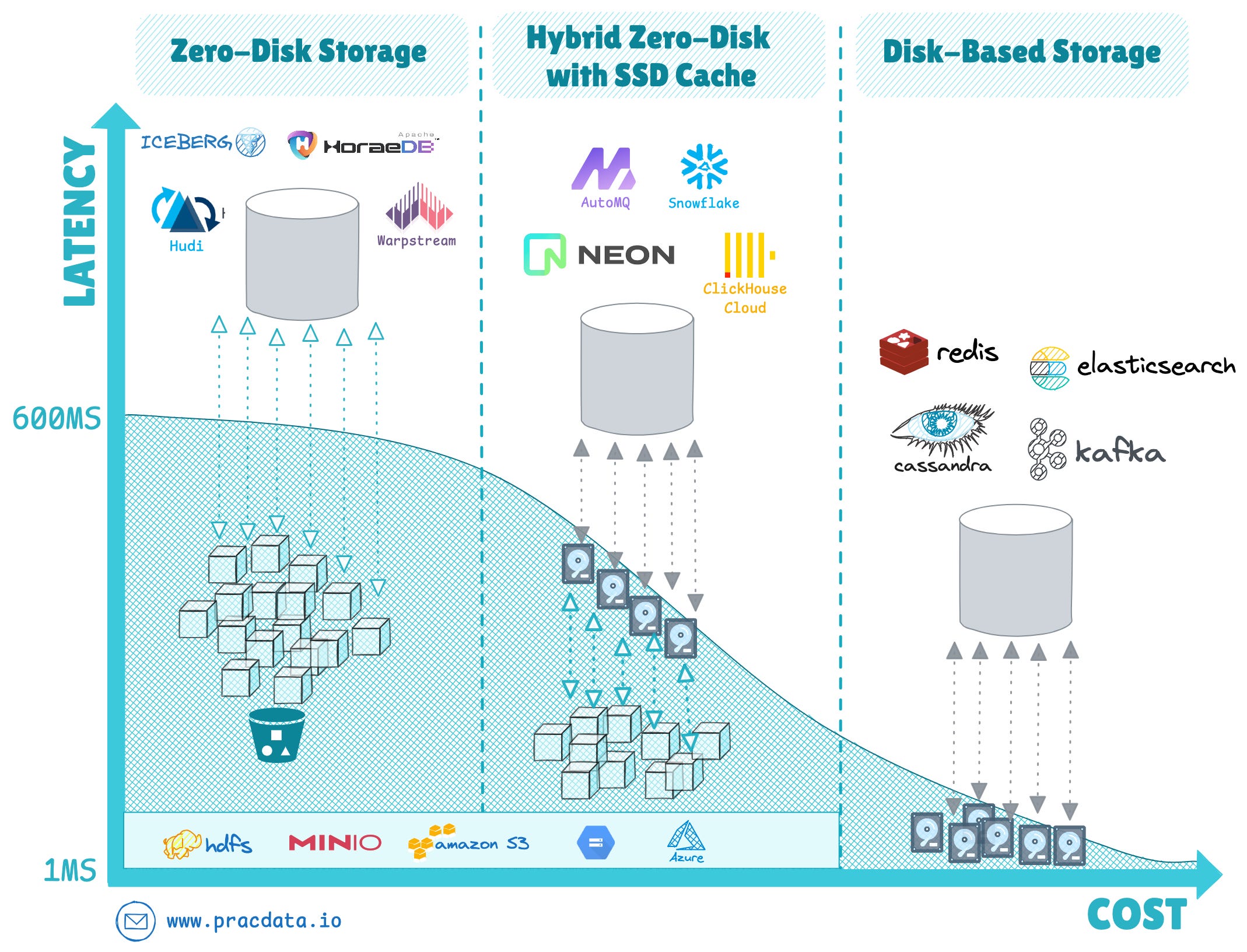
New database systems including SlateDB and Apache HoraeDB time-series database were built from the ground up with this architecture, while established systems like Apache Doris and StarRocks adopted it in 2024. Other real-time engines such as AutoMQ and InfluxDB 3.0 are increasingly adopting the zero-disk paradigm.
For a comprehensive analysis of zero-disk architecture and its implications, see the detailed exploration in the following article:

Other Notable Developments
Following Redis's move to a proprietary license in 2024, Valkey emerged as a leading open source alternative, becoming the most-starred storage system on GitHub in 2024. Major cloud providers quickly adopted it, with Google integrating it into Memorystore and Amazon supporting it through ElastiCache and MemoryDB services.
Other notable developments include ParadeDB, an alternative to Elasticsearch built on the PostgreSQL engine, and new hybrid streaming storage systems like Proton from TimePlus and Fluss introduced by Ververica. These systems aim to integrate streaming and OLAP functionalities with a columnar storage foundation.
2. Data Lake Platform
With database pioneer Michael Stonebraker endorsing the lakehouse architecture and open table formats as 'the OLAP DBMS archetype for the next decade', data lakehouse continues to be the hottest topic in data engineering.
The open table format landscape continued to evolve significantly in 2024. The forth major open table format, Apache Paimon graduated from incubation, bringing streaming lakehouse capabilities with Apache Flink integration. Apache XTable emerged as a new project focused on bi-directional format conversion, while Apache Amoro entered incubation with its lakehouse management framework.
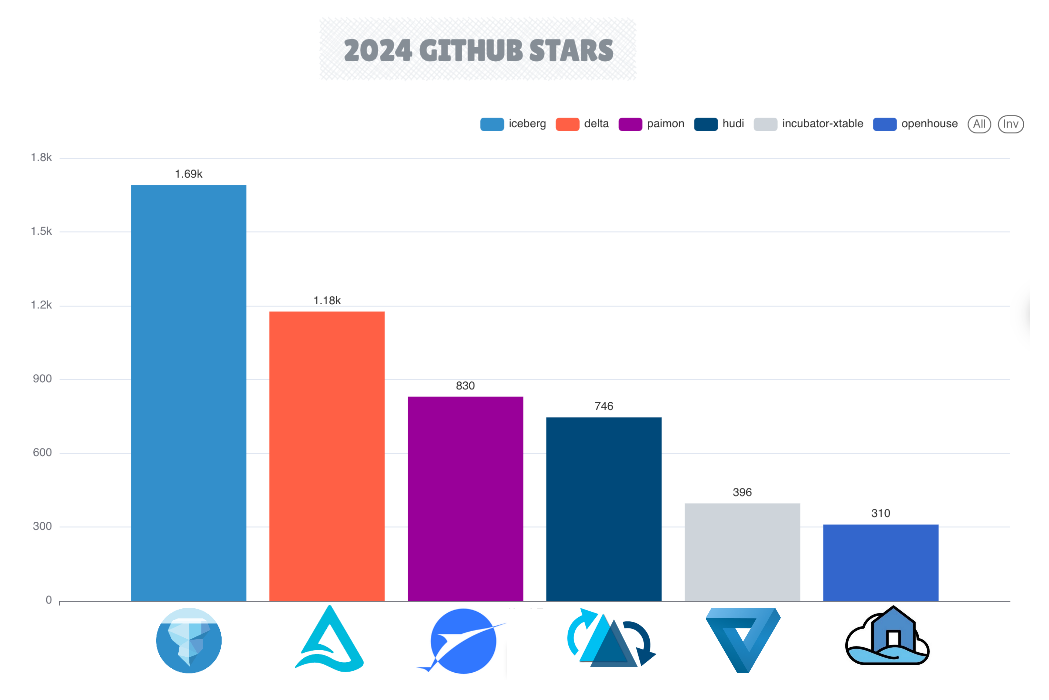
In 2024, Apache Iceberg has established itself as the leading project among open table format frameworks, distinguished by its ecosystem expansion and GitHub repository metrics, including a higher number of stars, forks, pull requests, and commits.
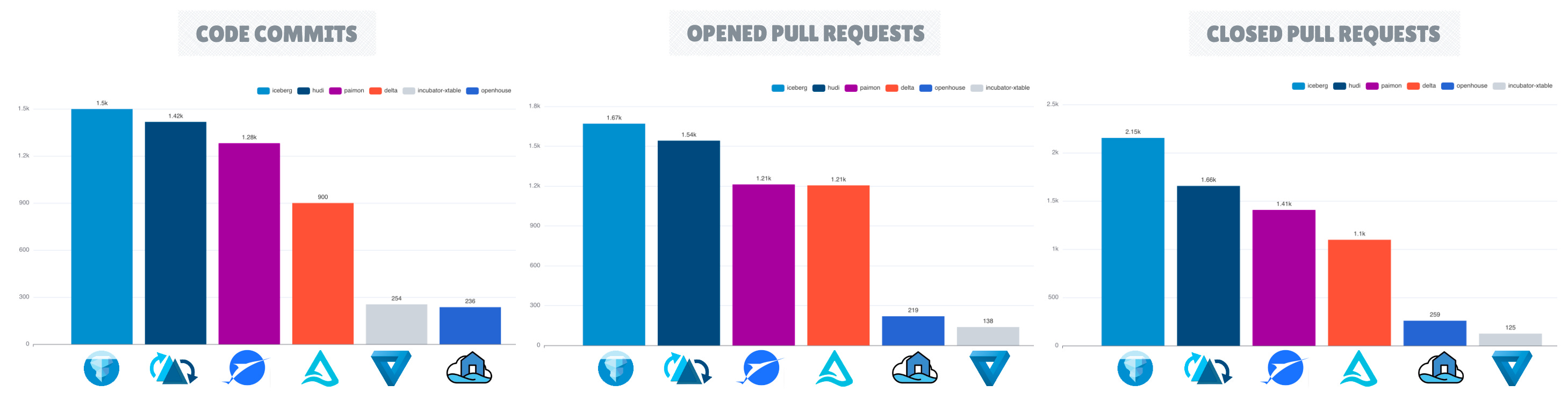
All major SaaS and cloud vendors have been enhancing their platforms to support access to open table formats. However, write support has been less prevalent, with Apache Iceberg being the preferred choice for comprehensive CRUD (Create, Read, Update, Delete) integration.
Google's BigLake Managed Tables, enabling mutable Iceberg tables within customer-managed cloud storage, Amazon's newly announced S3 Tables with native Iceberg support, and other major SaaS tools such as Redpanda launching Iceberg Topics and the Crunchy Data Warehouse deeply integrating with Apache Iceberg, are examples of increasing adoption and deep integration with Iceberg in the ecosystem.
Going forward universal table formats like Apache XTable and Delta UniForm (Delta Lake Universal Format) may face significant challenges in navigating the potential divergence of features across various formats, and the fate of open table formats may mirror that of open file formats, when Parquet emerged as the de facto standard.
As the lakehouse ecosystem continues to grow, the adoption of interoperable open standards and frameworks within an Open Data Lakehouse platform is expected to gain more popularity.
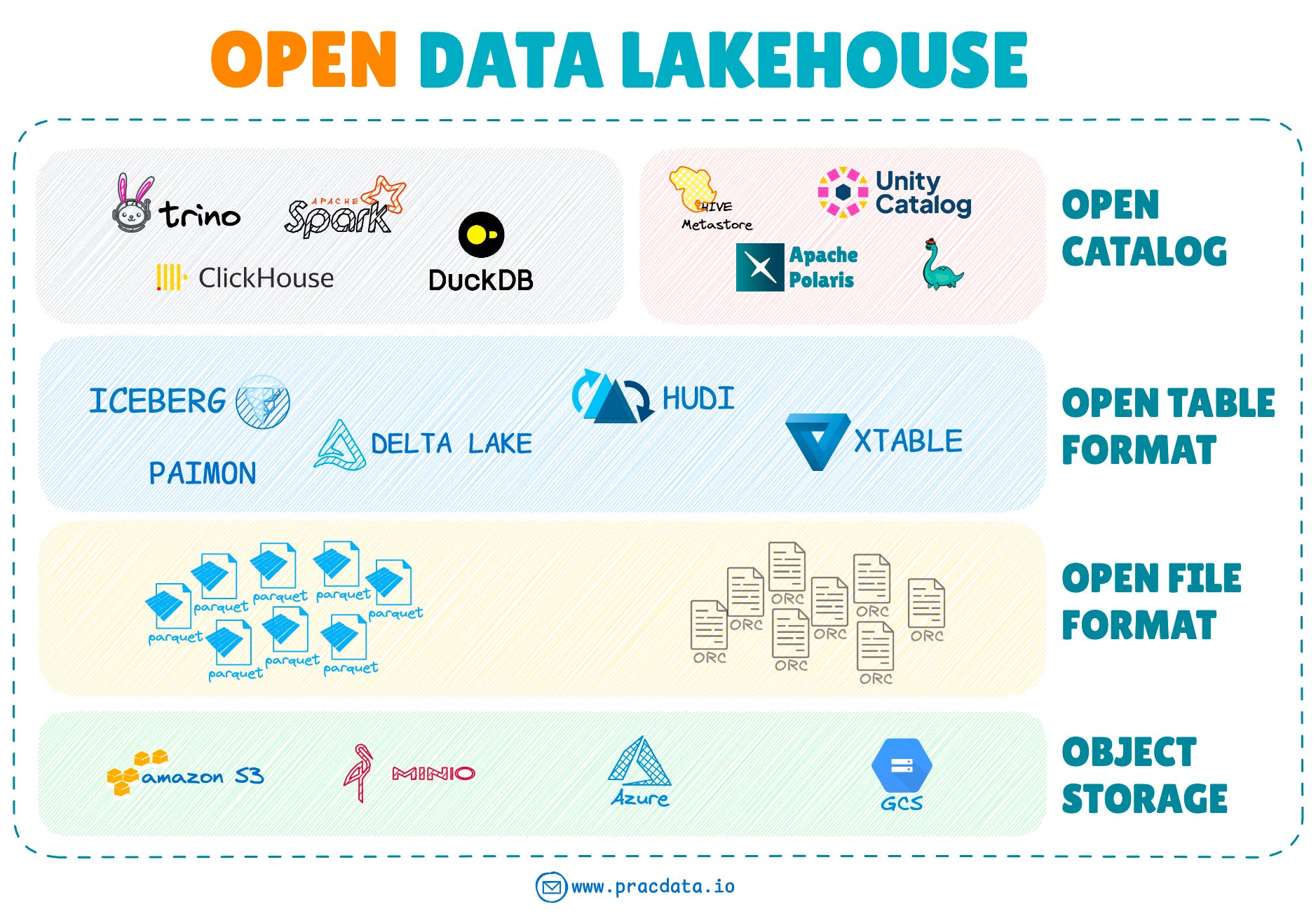
Emergence of Native Table Format Libraries
A new trend is emerging in the lakehouse ecosystem focused on developing native libraries in Python and Rust. These libraries aim to provide direct access to open table formats without the need for heavy frameworks like Spark.
Notable examples include Delta-rs, a native Rust library for Delta Lake with Python bindings; Hudi-rs, a Rust implementation for Apache Hudi with a Python API, and PyIceberg, an evolving Python library designed to enhance accessibility to the Iceberg table format outside the default Spark engine.
3. Data Processing & Integration
Rise of Single-Node Processing
The rise of single-node processing represents a fundamental shift in data processing, challenging traditional distributed-first approaches.
Recent analyses show that many companies have overestimated their big data needs, prompting a reassessment of their data processing requirements. Even in the organisations with large data volumes, approximately 90% of queries remain within manageable workload size to run on a single machine, only scanning recent data.
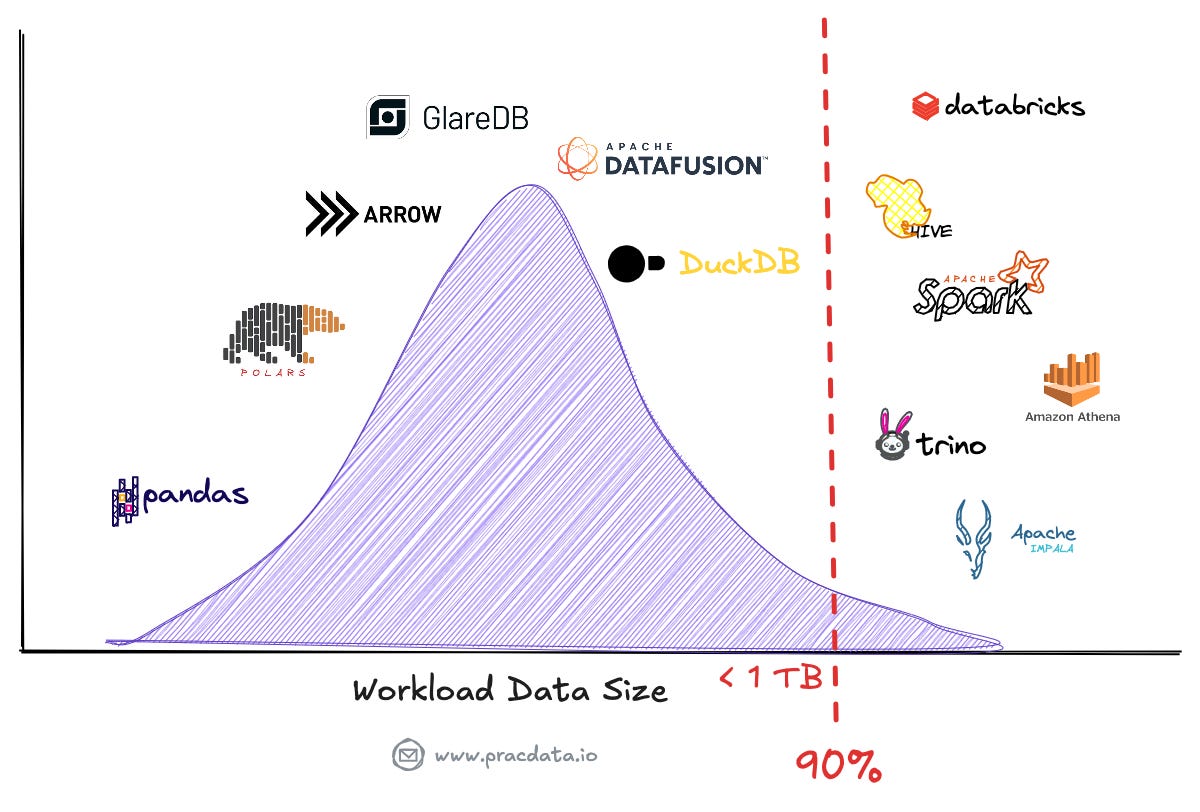
Modern single-node processing engines, such as DuckDB, Apache DataFusion, and Polars, have emerged as powerful alternatives, capable of handling workloads that previously necessitated distributed systems like Hive/Tez, Spark, Presto or Amazon Athena.
To explore the comprehensive analysis on the state of single-node processing, please follow the link below:

Stream Processing
The stream processing ecosystem continued to expand in 2024, with Apache Flink further solidifying its position as the premier streaming engine, while Apache Spark retains it’s strong position.
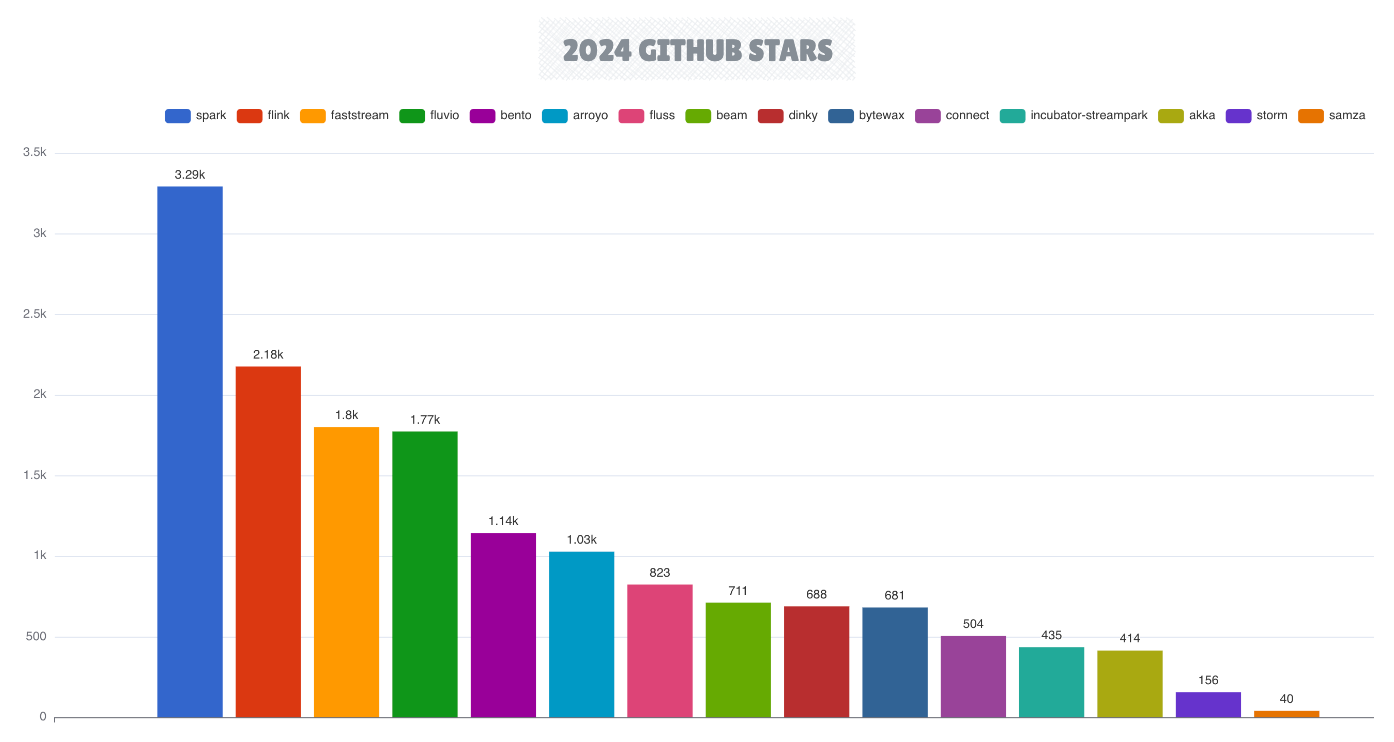
Celebrating its 10th anniversary, Flink released version 2.0, representing the first major update since Flink 1.0 debuted eight years ago. The Apache Flink ecosystem expanded significantly with the introduction of the Apache Paimon open table format and newly open sourced Fluss streaming engine. In 2024, leading cloud vendors have increasingly integrated Flink into their managed services, latest being Google’s serverless BigQuery Engine for Apache Flink solution.
Emerging streaming engines are Fluvio, Arroyo and FastStream, striving to compete with these established contenders. Fluvio and Arroyo stand out as the only Rust-based engines which aim to eliminate the overhead typically associated with traditional JVM-based stream processing engines.
In major open source streaming news, Redpanda acquired Benthos.dev, rebranding it as Redpanda Connect and transitioning it to a more proprietary license. In response, WarpStream forked the Benthos project, renaming it Bento and committing to keeping it 100% MIT-licensed.
Python Processing Frameworks
In the Python data processing ecosystem Polars is currently the dominant high-performance DataFrame library for data engineering workloads (excluding PySpark). Polars achieved an impressive 89 million downloads in 2024, marking a significant milestone with its 1.0 release.
However, Polars now faces competition from DuckDB's DataFrame API, which has captured the community's attention with its remarkably simple integration with external storage systems and zero-copy integration (direct memory sharing between different systems) with Apache Arrow—similar to Polars. Both libraries rank in the top 1% of the most downloaded Python libraries last year.
Apache Arrow has solidified its position as the de facto standard for in-memory data representation in the Python data processing ecosystem. The framework has established deep integration with various Python processing frameworks including Apache DataFusion, Ibis, Daft, cuDF, and Pandas 3.0.
Ibis and Daft are other innovative DataFrame projects with high potential. Ibis features a seamless back-end interface to various SQL-based databases and Daft provides distributed computing capabilities, built from the ground up to support distributed DataFrame processing.
4. Workflow Orchestration & DataOps
In 2025, open source workflow orchestration category continues to stand as one of the most dynamic segments of the data engineering ecosystem, featuring over 10 active projects that range from established platforms like Apache Airflow to newly open sourced engines like Netflix's Maestro.
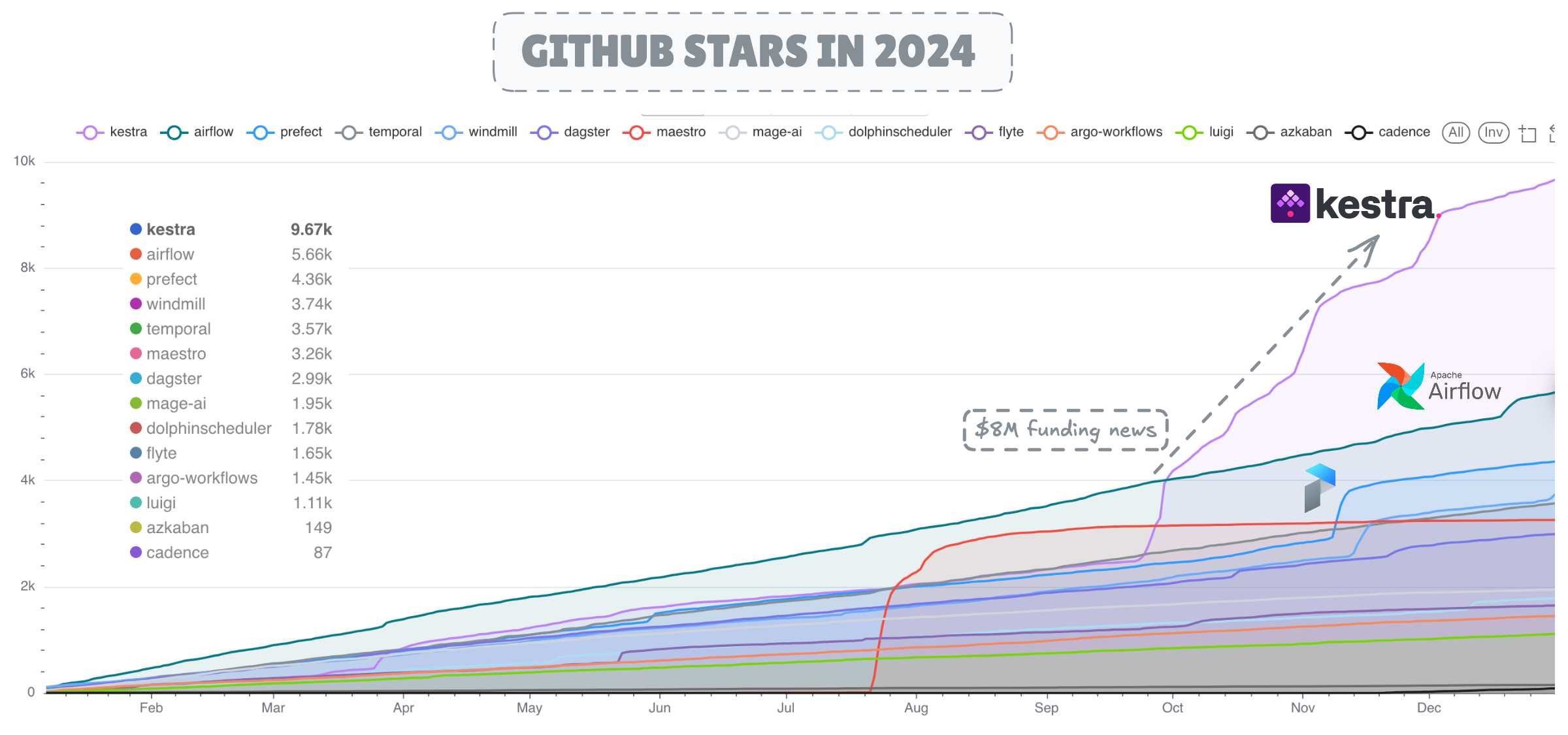
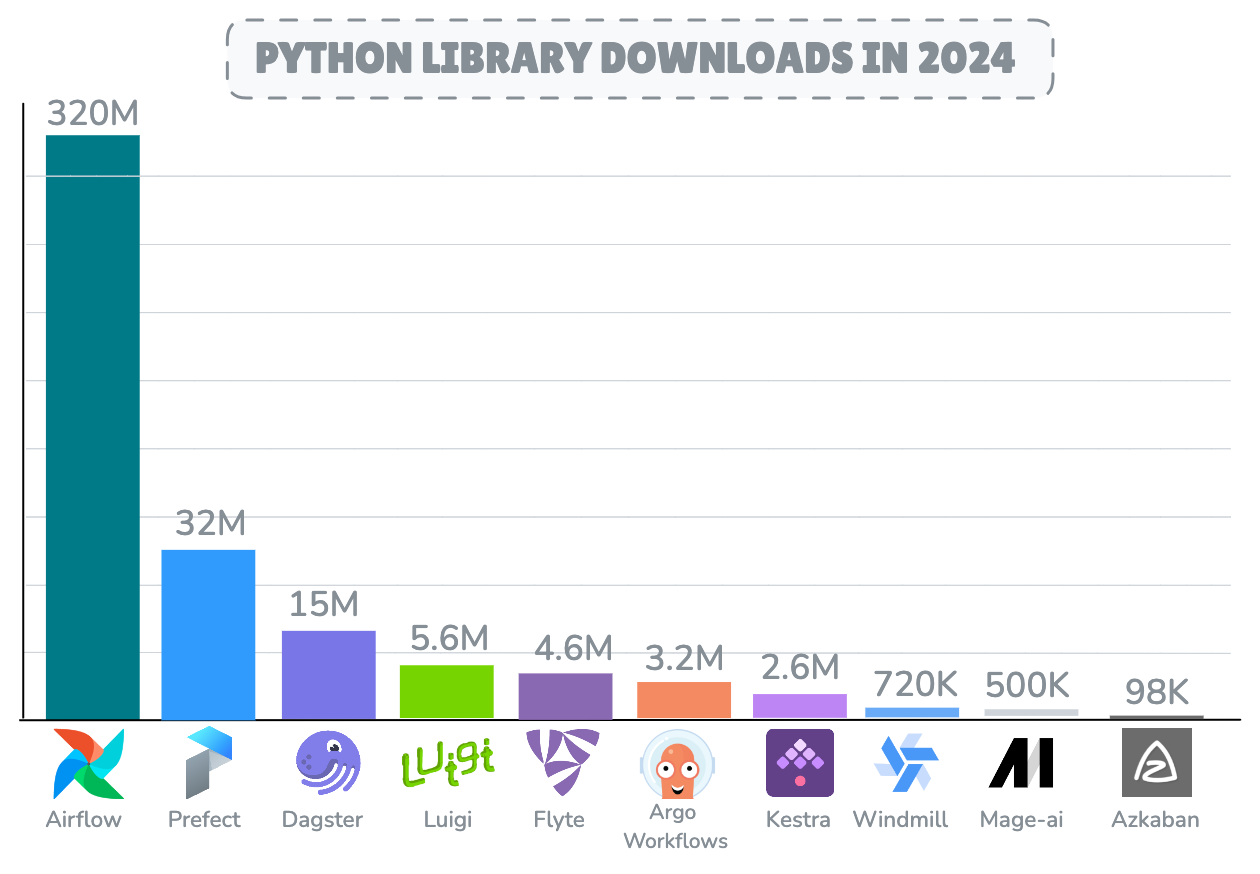
After a decade Apache Airflow continues to be the most deployed and adopted workflow orchestration engine with a staggering 320M downloads in 2024 alone, while facing competition from rising competitors such as Dagster, Prefect and Kestra.
Interestingly, Kestra gained the most stars on GitHub in 2024, with a surge directly linked to its $8M funding announcement in September, which was featured on TechCrunch. In terms of code activity, Dagster demonstrated remarkable development activity with an impressive 27K commits and close to 6K pull requests closed in 2024.
For comprehensive analysis on the state of workflow orchestration systems, read the following article:

Data Quality
Great Expectations continues to be a leading Python framework for data quality and validation also featured in Databrick's Top 10 Data and AI productions of 2024 , followed closely by Soda and Pandera in the data engineering practice. However, there is some disappointing news: the Data-Diff project has been archived by its main maintainer, Datafold in 2024.
Data Versioning
Data Versioning remains a prominent topic in 2024, as efforts continue to bring the capabilities of modern version control systems, like Git, to data lakes and lakehouses.
Projects like LakeFS and Nessie, enhance modern data lakes and open table formats such as Iceberg and Delta Lake by extending their transactional metadata layers.
Data Transformation
The scope of using dbt for data transformation is expanding beyond its original focus on data modeling within data warehouse systems. It is now making inroads into off-warehouse environments, such as data lakes, through new integrations and plugins that leverage ephemeral compute engines like Trino.
Currently, dbt faces competition primarily from SQLMesh. A notable stand-off in 2024 was the SQLMesh vs. dbt debate, highlighted by Tobiko's CEO, who claimed on social media that SQLMesh is so good it's banned from dbt's Coalesce conference!
5. Data Integration
In the data integration space, Airbyte maintained its leadership position, achieving an impressive milestone by closing 13K pull requests in preparation for version 1.x. The dlt framework demonstrated significant maturation with its 1.0 release, while Apache SeaTunnel gained traction as a compelling alternative.
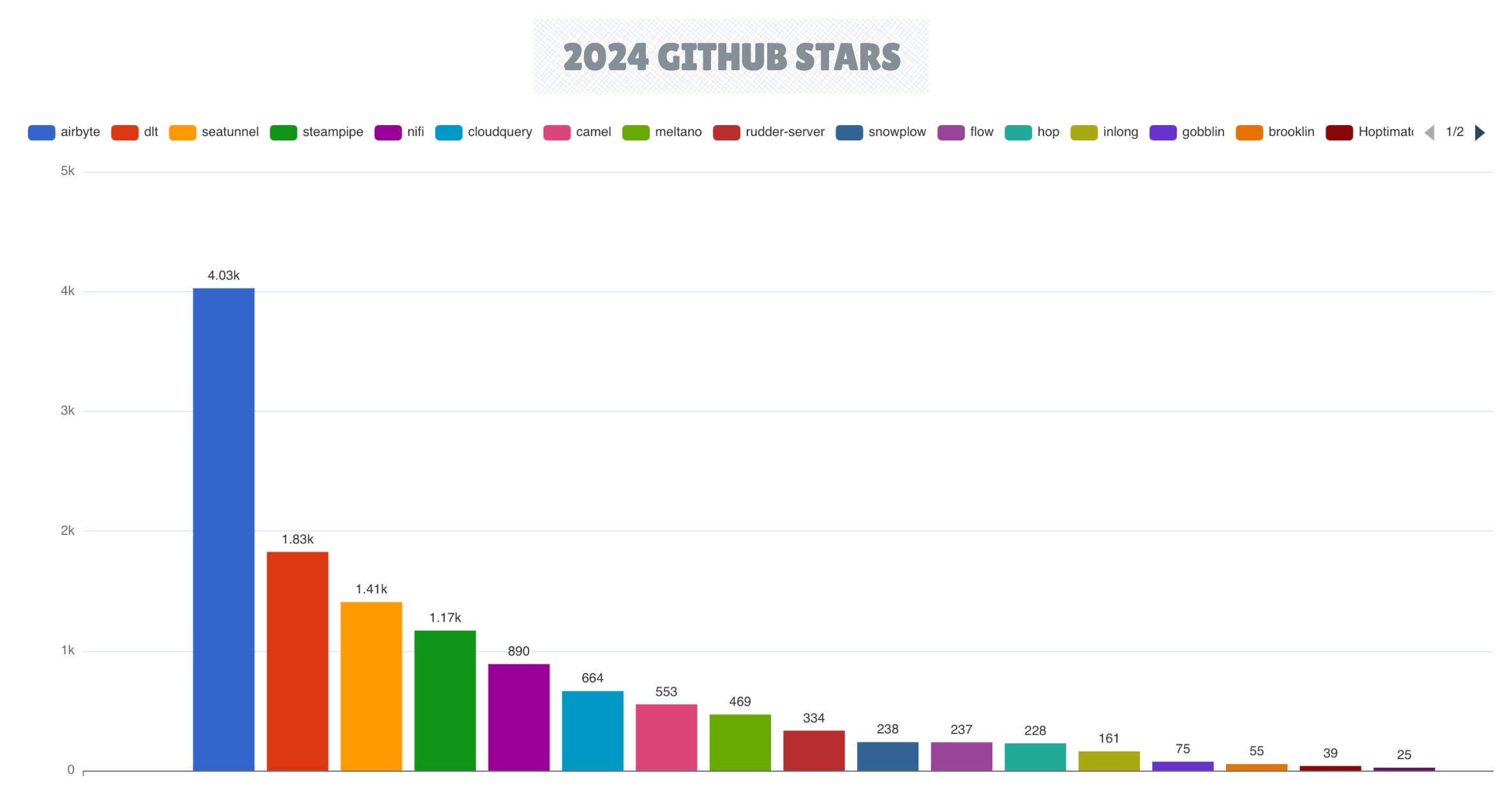
The Change Data Capture (CDC) framework landscape evolved with new tools including Artie Transfer and PeerDB (acquired by ClickHouse), while Flink CDC connectors gaining adoption among platforms using Flink as their primary streaming engine.
Event Hubs (Streaming Pub/Sub Services)
One of the most notable innovations in the data integration space in 2024 came from the evolving data streaming landscape. A significant architectural shift in this category is the separation of storage and compute, coupled with the adoption of object storage in a zero-disk architecture. WarpSteram is a pioneer of implementing this architecture in real-time streaming space.
This model also enables a flexible Bring Your Own Cloud (BYOC) deployment strategy, as both compute and storage can be hosted on the customer's preferred infrastructure, while the service provider maintains the control plane.
WarpStream's success has prompted major competitors to adopt similar architectures. Redpanda launched Cloud Topics, enhancing its offerings, while AutoMQ implemented a hybrid approach featuring a fast caching layer to improve I/O performance.
Additionally, StreamNative introduced the Ursa engine for Apache Pulsar, and Confluent unveiled its own cloud-native Freight Clusters in 2024. Ultimately, Confluent decided to acquire WarpStream, further expanding its offering with BYOC model. Meanwhile, the remarkable Apache Kafka stands at a crossroads that may define its future direction in the ecosystem.
6. Data Infrastructure
The data infrastructure landscape in 2024 remained largely stable, with Kubernetes celebrating its 10th anniversary while maintaining its position as the leading resource scheduling and virtualisation engine in cloud environments.
In the observability space, InfluxDB, Prometheus, and Grafana continued their dominance, with Grafana Labs securing a notable $270M funding round that reinforced the long-term viability of their core products like Grafana as general-purpose observability solutions.
7. ML/AI Platform
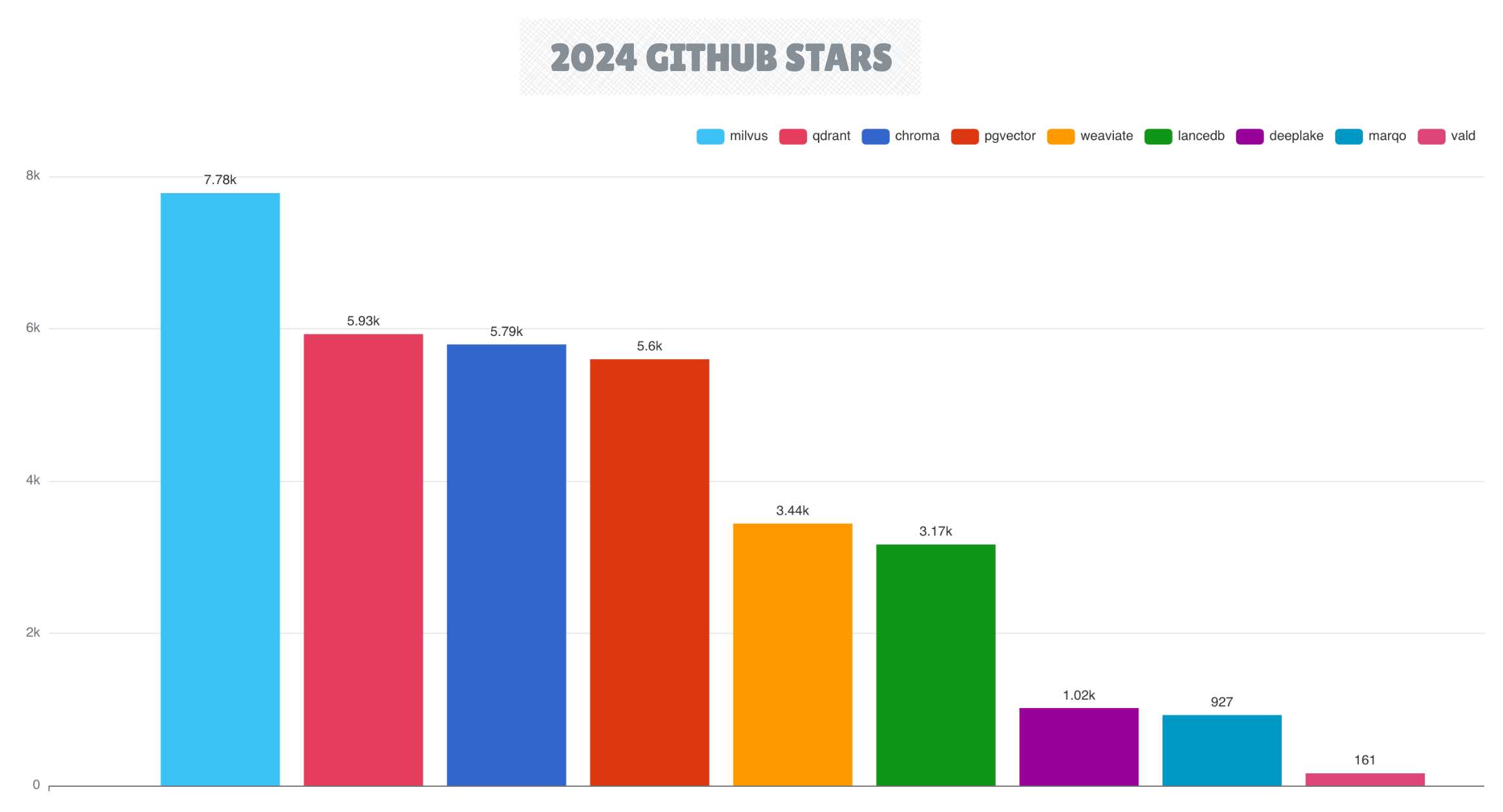
Vector databases maintained strong momentum from 2023, with Milvus emerging as a leader alongside Qdrant, Chroma, and Weaviate. The category now encompasses ten active vector database projects, reflecting the growing importance of vector search capabilities in modern AI-enabled data architectures.
The introduction of LLMOps (also referred to as GenOps) as a distinct category in this year's presented landscape was marked by the rapid growth of new projects like Dify and vLLM purposefully built for managing LLM models.
8. Metadata Management
Metadata management platforms have gained significant momentum in recent years, with DataHub leading the open source space through its active development and community engagement.
However, the most notable developments in 2024 occurred in catalog management. While 2023 was dominated by competition in open table formats, 2024 marked the beginning of the Catalog War.
In contrast to earlier years, 2024 brought a wave of new open catalog solutions to the market, including Polaris (open sourced by Snowflake), Unity Catalog (open sourced by Databricks), LakeKeeper, and Apache Gravitino.
This proliferation reflects the realisation that emerging data lakehouse platforms, which rely heavily on open table formats, lack advanced built-in catalog management capabilities for seamless multi-engine interoperability.
All of these projects have the potential to establish a new standard for vendor-agnostic, open catalog services in data lakehouse platforms. Much like Hive Metastore became the de facto standard for Hadoop-based platforms, these emerging catalogs may finally replace Hive Metastore's long-standing dominance in catalog management on open data platforms.
9. Analytics & Visualisation
In the open source Business Intelligence realm, Apache Superset and Metabase remain the leading BI solutions. While Superset leads in GitHub popularity, Metabase shows the highest development activity. Lightdash emerged as a promising newcomer, securing $11 million in funding and demonstrating market demand for lightweight BI solutions.
BI-as-Code Solutions
BI-as-Code emerged as a distinctive category, driven by the continued success of Streamlit, which maintained its position as the most popular BI-as-Code solution.
These tools enable developers to create interactive apps and lightweight BI dashboards using code, SQL and templates like Markdown or YAML, being able to combine the software engineering best practices, such as version control, testing and CI/CD into the dashboard development workflow.
In addition to Streamlit and the well-known Evidence, new entrants like Quary and Vizro have gained traction, with Quary notably implementing a Rust-based approach that diverged from the Python-centric norm of the category.
Composable BI Stack
The evolution of system decomposition is not limited to storage systems; it has also impacted Business Intelligence (BI) stacks. A new trend is emerging that combines lightweight, bottomless BI tools (which don't have a back-end server) with headless embeddable OLAP solutions such as Apache DataFusion, Apache Arrow, and DuckDB.
This integration addresses several gaps in the the open source BI stack such as native ability to query external data lakes and lakehouses while preserving the benefits of lightweight, disaggregated architectures.
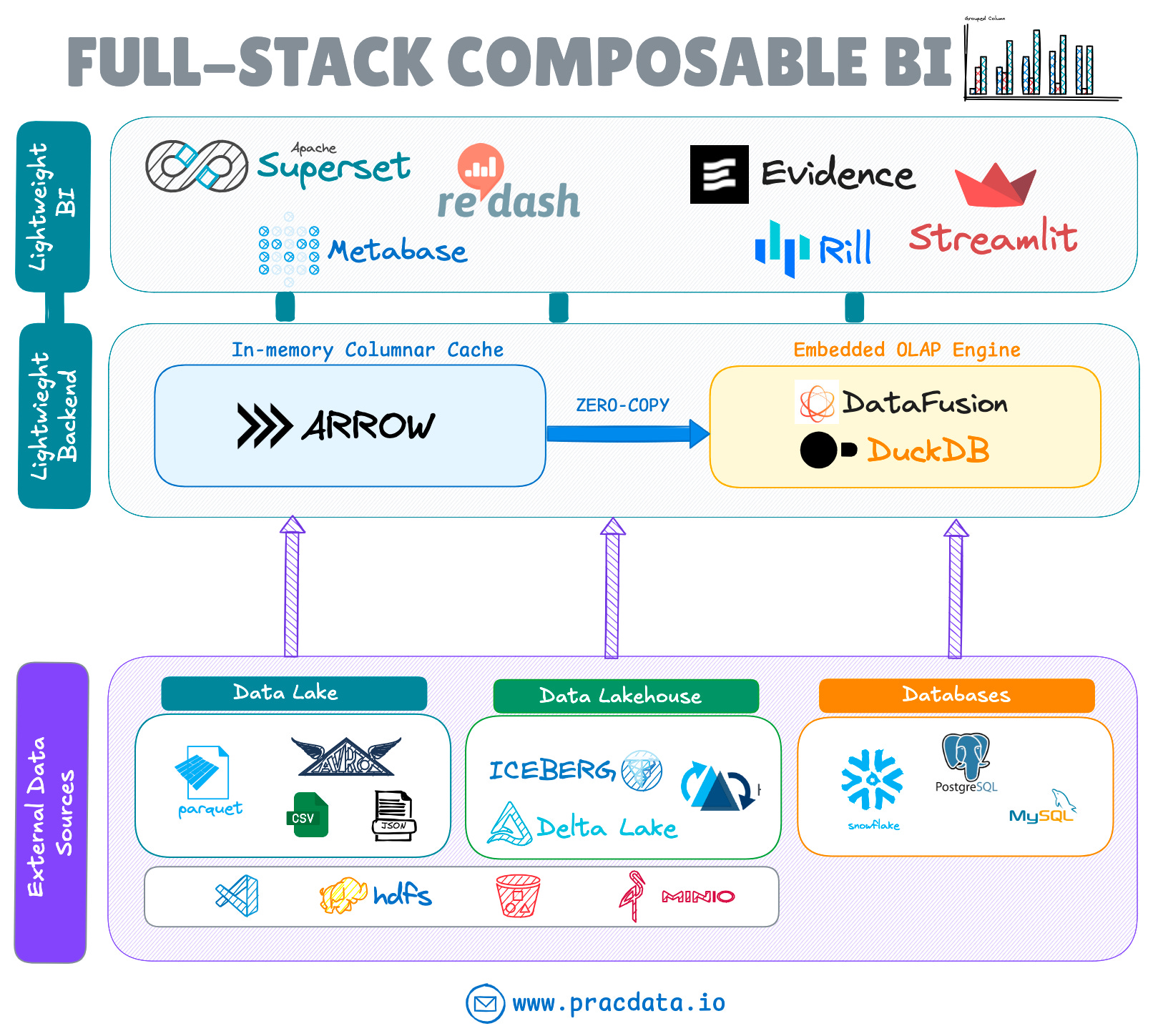
BI Products like Omni, GoodData, Evidence, and Rilldata have already incorporated these engines into their BI and data exploration tools. Both Apache Superset (using the duckdb-engine library) and Metabase now support embedded DuckDB connections.
For a comprehensive analysis of the evolving composable BI architecture, see the detailed exploration in the following article:

MPP Query Engines
Post-Hadoop era there has been little innovation and introduction of new open source MPP (Massively Parallel Processing) systems while existing engines continue to mature.
While Hive's share is shrinking, Presto and Trino still remain as top open source MPP query engines used in production, despite facing fierce competition from Spark as a unified engine, and managed cloud MPP products such as Databricks, Snowflake and AWS Redshift Spectrum plus Athena.
Future Outlook and Conclusion
The open source data ecosystem is entering a phase of maturity in key areas such as data lakehouse, characterised by consolidation around proven technologies and increased focus on operational efficiency.
The landscape continues to evolve toward cloud-native, composable architectures while standardising around dominant technologies. Key areas to watch include:
Further consolidation in the open table format space
Continued evolution of zero-disk architectures in real-time and transactional systems
Quest toward providing a unified lakehouse experience
The rise of LLMOps and AI Engineering
The expansion of the data lakehouse ecosystem in areas such as open catalog integration and development of native libraries
The increasing traction of single-node data processing and embedded analytics

Thanks 🙏🏻 this is awesome 🔥
I've been reading your work recently and have become a fan. Your research is incredibly detailed and comprehensive—thank you for all your hard work!